


{kind=link}
In the realm of AI model optimization, Hugging Face has once again taken a pioneering step with the introduction of its latest AI models, the SmolVLM-256M and SmolVLM-500M. These innovative models are specifically crafted to revolutionize performance on low-RAM devices, offering a compact yet powerful solution for developers and data scientists. What sets these models apart is not just their efficiency but also their accessibility, being available under the Apache 2.0 license for unrestricted use.
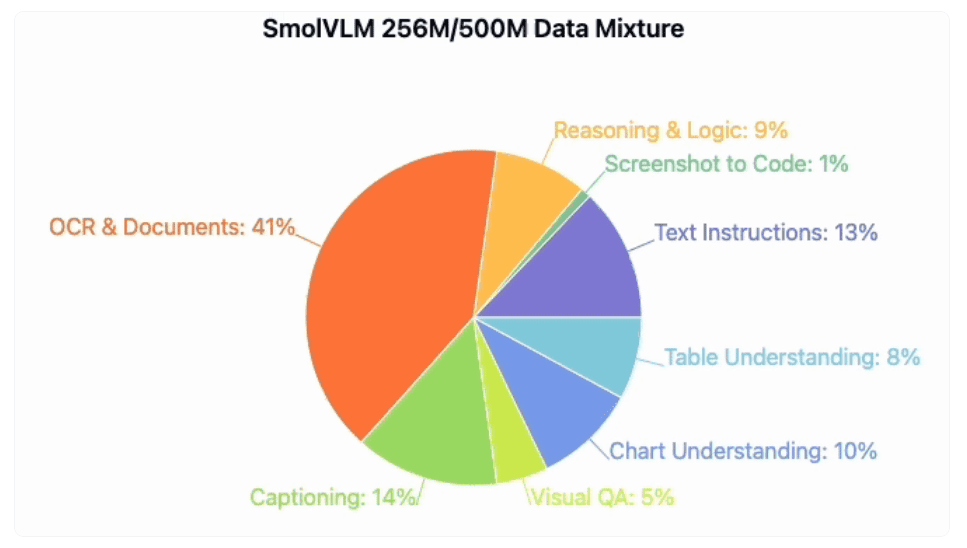
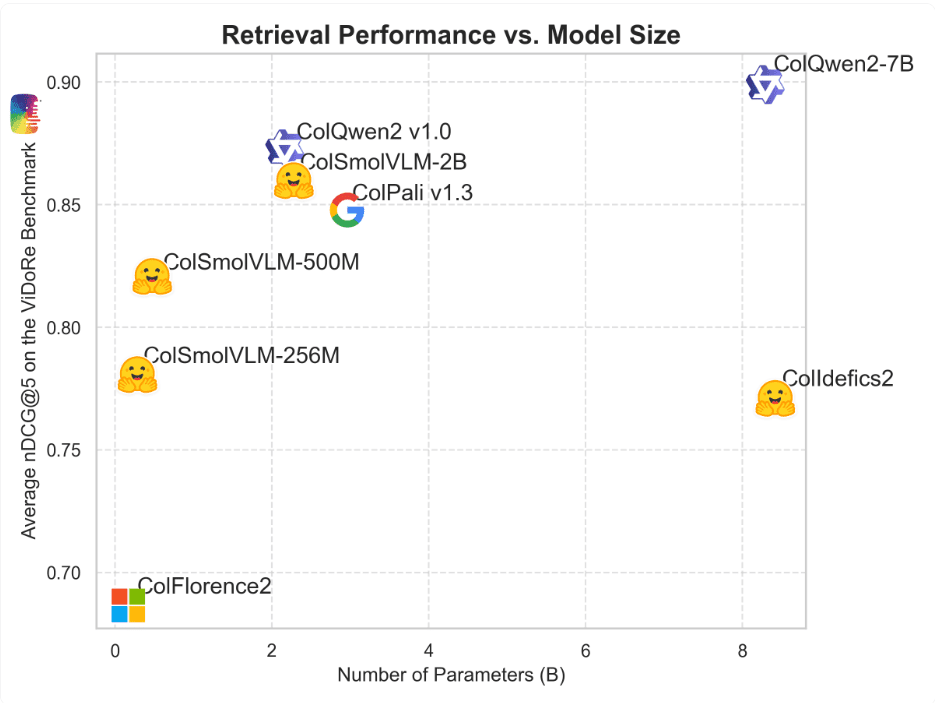
The Power of SmolVLM Models
The SmolVLM-256M and SmolVLM-500M models stand out for their remarkable compact size, catering to the needs of devices with limited resources without compromising on performance. Designed for tasks encompassing text, image, and video analysis, these models utilize advanced optimization techniques to reduce memory usage and enhance overall efficiency. By outperforming larger models on benchmarks, the SmolVLM series showcases the prowess of AI innovation in delivering significant results even with constrained resources.
A Boon for Developers
For developers grappling with limited resources, the SmolVLM models emerge as a beacon of hope, offering unparalleled benefits for those working on laptops and other low-memory environments. Tailored to be developer-friendly, these models not only streamline processing but also pave the way for cost-effective and efficient data analysis. The applications of SmolVLM-256M and SmolVLM-500M extend to edge computing scenarios, where optimized performance is crucial for success in diverse AI projects.
Using Smaller SmolVLM Models
Get started with SmolVLM Model using transformers like below.
import torch
from transformers import AutoProcessor, AutoModelForVision2Seq
# Initialize processor and model
processor = AutoProcessor.from_pretrained("HuggingFaceTB/SmolVLM-500M-Instruct")
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-500M-Instruct",
torch_dtype=torch.bfloat16,
_attn_implementation="flash_attention_2" if DEVICE == "cuda" else "eager",
)
# Create input messages
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "Can you describe this image?"}
]
},
]
# Preprocess
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=[image], return_tensors="pt")
# Generate
generated_ids = model.generate(**inputs, max_new_tokens=500)
generated_texts = processor.batch_decode(
generated_ids,
skip_special_tokens=True,
)The CLI Command:
python3 -m mlx_vlm.generate --model HuggingfaceTB/SmolVLM-500M-Instruct --max-tokens 400 --temp 0.0 --image https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/vlm_example.jpg --prompt "What is in this image?"Embracing the Future with SmolVLM Models
In concluding thoughts, Hugging Face’s call to action resonates strongly with developers and data scientists alike. By encouraging exploration and utilization of the SmolVLM models, Hugging Face invites the community to delve into the realm of AI optimization, backed by cutting-edge solutions. To embark on this transformative journey, access the models and resources provided, and witness firsthand the impact of SmolVLM-256M and SmolVLM-500M in reshaping data processing on low-RAM devices.
This blog post serves as a testament to the evolution of AI models and the pivotal role that Hugging Face plays in driving innovation towards efficiency, accessibility, and performance optimization. Join the movement today and embrace the future of data processing with Hugging Face’s SmolVLM models.